What to Watch? (Part One)
Summary of Deliverables
This assignment is broken up into two major parts. In the first, you will be responsible for scraping reviews of movies from a set of pages on the internet. In the second, you will visualize your collection of movie reviews and build some simple tools for algorithmic recommendation.
By the end of this first part, here’s what you’ll need to submit to Gradescope:
scraping.pyreadme_scraping.txt
Notes & Advice
We are intentionally providing you much less guidance than you have received on previous assignments. This is for a couple of reasons. For one, part of the “joy” of scraping is poking around on a webpage until you understand its structure. For another, we want you to have the opportunity to work on a more open-ended assignment so that you can confirm your own coding maturity and independence.
Since there are fewer step-by-step instructions, you should feel free to take an approach that makes the most sense to you. Because you will be making a number of independent decisions, it’s vital that you start this assignment as soon as you can. You should also go to Office Hours proactively rather than reactively: it is much easier for a TA to confirm or adjust your understanding of an approach before you try it than to try to “dig you out” of an overly complicated approach after the fact.
Part 1: Scraping
If you need to restart your project, you can find the scraping starter file here.
Structure of the Webpages
If you navigate to the following link (https://www.cis.upenn.edu/~cis110/movies/large_movies/page_1.html), you’ll see a simple HTML page containing a few components: a table containing information about a bunch of movies, and a pagination element for navigating to other pages in the movie dataset.
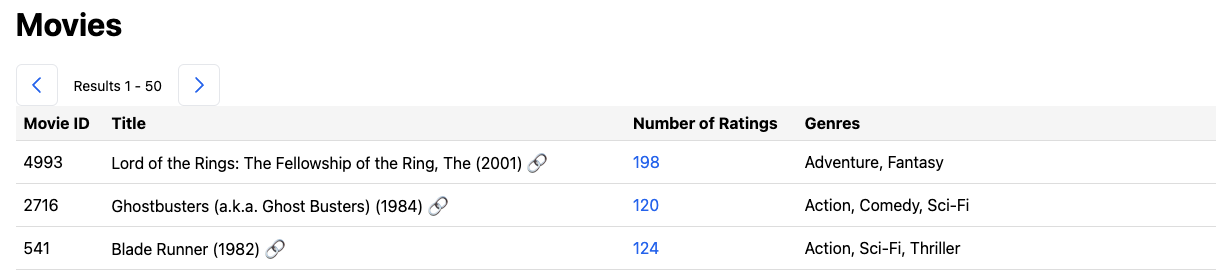
The table has a regular structure where one row represents a few key pieces of information about a single movie. Those information attributes are stored in the columns Movie ID, Title, Number of Ratings, and Genres.
Observe that there are actually two links in each row of the table: one is a link to that movie’s IMDB page, and another is a link to the list of reviews that we have collected for that movie. The IMDB link is there for the reader’s convenience, and the link to the movie’s reviews will be useful for you in a future step.
Above the table, you’ll observe a widget that tells you which movies of the dataset are displayed on the current page. This widget also features a forward and a backward arrow that contain links to the next and previous page of results, respectively. (When there is no previous or next page, that arrow will link to the current page instead.)
The URL linked above, http://www.cis.upenn.edu/~cis110/movies/large_movies/page_1.html, represents Page 1 of the large_movies review dataset. If we click the “Next” arrow, we’re taken to http://www.cis.upenn.edu/~cis110/movies/large_movies/page_2.html, which represents Page 2 of the large_movies review dataset.
Quick check:
- What would be the URL for Page 37 of the
large_moviesreview dataset?- What would be the URL for Page 2 of the
tiny_moviesreview dataset?
If we navigate to the link under the Number of Ratings column, we’ll end up on a page that looks like the following:
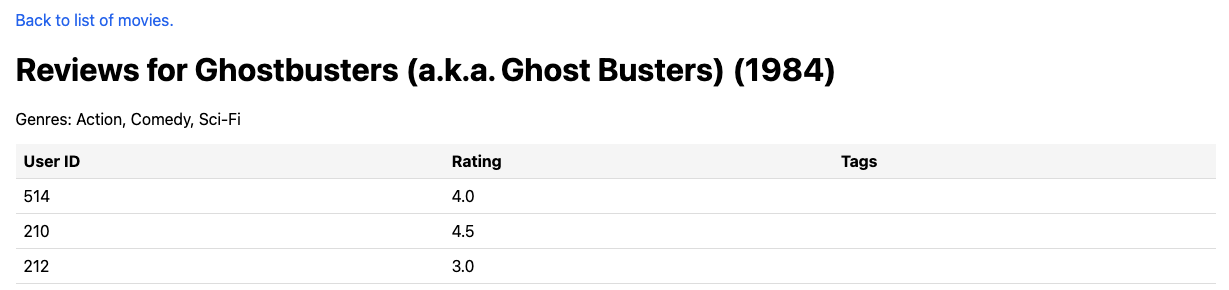
This page is for the movie Ghostbusters (1984). This movie has the ID of 2716 in the large_movies dataset, and so it lives at the URL http://www.cis.upenn.edu/~cis110/movies/large_movies/ratings_2716.html.
Quick check:
- What would be the URL for ratings of movie 2337 of the
large_moviesreview dataset?
This page lists the genres for the movie, as well as a link back to Page 1 of movies in this dataset and a table of all ratings available for this movie. These ratings are all made by a user with a unique ID, and all ratings are numbers between 0 and 5. Some users provided tags for their ratings as well. (One user helpfully tagged Ghostbusters (1984) with the tag “ghosts”. Thank you, very cool!)
Collecting Movie Info
The first function to implement is scrape_movie_info(). The signature is as follows:
def scrape_movie_info(slug: str) -> dict[int, tuple[str, tuple[str]]]:
...
Given a slug that represents the prefix used for all pages in the current dataset, return a dictionary that maps each movie ID to that movie’s info. The movie’s info is modeled as a tuple containing the name of the movie as well as a tuple of its genres.
For the tiny_movies dataset that’s hosted on the course website, the slug would be the following string: "https://www.cis.upenn.edu/~cis110/movies/tiny_movies/". Your code should work to scrape different datasets, though, so it’s important that you don’t “hard code” in any particular slug value: use the input to the function!
Here is an example of the structure that scrape_movie_info should return:
{
780: ("Ocean's Eleven", ("Crime", "Thriller")),
1214: ("Alien", ("Horror", "Sci-Fi"))
}
Note that this doesn’t correspond to a full result and it is only provided as an example of the correct structure of the answer.
When we refer to “each movie ID” and “all pages in the current dataset”, we are referring to every movie on every page reachable by clicking the next button starting on page_1.html. That page links to page_2.html, which therefore should have its movies included. This second page also contains a link to page_3.html, which should have its movies included. And so on, and so on. The last page in each dataset has an empty string as its next page link—this behavior can be used as a sign to end the scraping process.
Keep in mind the following:
- Different datasets have different numbers of movie pages.
tiny_movieshas three pages whereassmall_movieshas five. There is no way a priori to know how many movie pages each dataset has. - Different datasets have different numbers of movies per page.
tiny_movieshas 2, whereassmall_movieshas 8. There is no way a priori to know how many movies per page there will be. - The table on each page listing movies will always have exactly the same structure.
- You need to scrape the titles of the movies, but the table entries have the years included as part of that information. You’ll need to extract only the title part of the movie. Don’t forget about all of the string methods we’ve discussed:
strip(),split(), and slicing will all be helpful; others listed in the documentation likestartswith()orendswith()might also be of use.
Check Your Work
There are a couple of unit tests made available to you in test_scrape_movie_info.py. There is a “tiny” test and a “small” test that is commented out—don’t try to run the small one until you pass the tiny one! Since you’re actually loading data over the internet, this code takes some time to run! Remember how to run your unit tests:
python -m unittest test_scrape_movie_info.py
You might get a test failure with a message that looks something like this:
Test Failed: {'2':[54980 chars], The ', ['Drama']], '72737': ['Princess and t[7578 chars]i']]} !=
{'2':[54980 chars], The', ['Drama']], '72737': ['Princess and th[7577 chars]i']]}
It’s hard to spot, but the difference is in the space after the title of your movie. Make sure your strings are all stripped of whitespace on either side after you remove the release year.
You might get a test failure with a message that looks something like this:
Test Failed:
{'17'[720 chars]l (KÃ\x83´kaku kidÃ\x83´tai)', ['Animation',[4444 chars]y']]} !=
{'17'[720 chars]l (Kôkaku kidôtai)', ['Animation', 'Sci-Fi'][4429 chars]y']]}
Different ways of “decoding” the response received by your request will lead to different interpretations of characters with diacritics (accents). Make sure that you use the .text attribute of your response object, not something else like .contents.
Collecting User Ratings
The second function to implement is scrape_ratings(). The signature is as follows:
def scrape_ratings(slug: str, movie_ids: set[int]) -> dict[int, dict[int, float]]:
...
Given a slug and a set movie_ids that contains all of the movie IDs available in a dataset, return a dictionary that stores all ratings made by all users. The dictionary returned should map user IDs to dictionaries containing all of that user’s ratings. Each inner dictionary will map movie IDs to the score that the user provided for that movie ID.
Keep in mind that the ratings for a movie with id n are found at the URL of f"{slug}ratings_{n}.html"
Here is an example of the structure of the nested dictionary that scrape_ratings should return:
{
514: {
2716: 5.0,
780: 2.0
},
279: {
780: 4.0,
300: 2.5,
1010: 0.5
}
}
In the example dictionary above, we have modeled a dataset that contains two different users, four different movies, and five different ratings.
Quick check:
- What rating did the user with ID
279give to the movie with ID300?- What is the ID of the movie that both users rated? Who gave it the higher rating?
Check Your Work
Here is the intended result of calling scrape_movie_info("https://www.cis.upenn.edu/~cis110/movies/tiny_movies/"):
{1210: ('Star Wars: Episode VI - Return of the Jedi',
('Action', 'Adventure', 'Sci-Fi')),
2028: ('Saving Private Ryan', ('Action', 'Drama', 'War')),
1307: ('When Harry Met Sally...', ('Comedy', 'Romance')),
5418: ('Bourne Identity, The', ('Action', 'Mystery', 'Thriller')),
56367: ('Juno', ('Comedy', 'Drama', 'Romance')),
3751: ('Chicken Run', ('Animation', 'Children', 'Comedy'))}
If we save the above result into a variable, we could get all of the movie IDs into a set like so:
movie_info = scrape_movie_info("https://www.cis.upenn.edu/~cis110/movies/tiny_movies/")
movie_ids = set(movie_info.keys())
We could then call scrape_ratings("https://www.cis.upenn.edu/~cis110/movies/tiny_movies/", movie_ids). This would return a dictionary with 331 entries, representing the reviews of 331 users. You should spot check your output to make sure that you see the matching ratings from each user associated with each movie. For example, you should verify that your output has a review for “When Harry Met Sally…” and “Star Wars: Episode VI - Return of the Jedi” from user #600.
You can compare your output of the tiny movies dataset with the correct movie info and user ratings if you like. There are a couple of unit tests made available to you in test_scrape_ratings.py. There is a “tiny” test and a “small” test that is commented out—don’t try to run the small one until you pass the tiny one! Since you’re actually loading data over the internet, this code takes some time to run!
python -m unittest test_scrape_ratings.py
Correct outputs for other datasets are also linked here:
| Movie Info | Ratings | |
|---|---|---|
| small | 🔗 | 🔗 |
| medium | 🔗 | 🔗 |
| large | 🔗 | 🔗 |
(or, you can also download all of them altogether here.)