A Quick Introduction to SuperTagging and its Applications
http://www.cis.upenn.edu/~xtag/supertags
SuperTagging 101: The Basics
SuperTagging [Joshi and Srinivas, 1994,Srinivas, 1997a]
is an approach to syntactic annotation
based on Lexicalized Tree Adjoining Grammar
(LTAG) [Schabes et al., 1988].
In some ways, SuperTags resemble part of speech (POS) tags, and thus it is useful to take a brief look at POS tagging. POS taggers typically use a limited tagset (the Penn Treebank uses a tagset of about 40 tags). While such tagsets distinguish between singular and plural nouns (NN and NNS, NNP and NNPS), and different verbal categories (past, participle, continuous: VBD, VBN, VBG respectively) etc. besides the standard noun, adjective, adverb etc. categories, there is typically no discrimination, for instance, between the use of the word to as a preposition and as an infinitival marker or between for as a complementizer and as a preposition.
Figure 1 depicts the POS tags assigned to each word of the phrase The woman who was appointed by the Governor and the sentence She was appointed by the Governor in 1998.

SuperTags are analogous to the primary elements of the LTAG formalism, which localize dependencies, including long distance dependencies, by requiring that all and only the dependent elements be present within the same structure. Thus SuperTags contain more information (such as sub-categorization and some attachment information) than standard POS tags. There is one SuperTag for each syntactic environment that a word appears in. Hence there are many more SuperTags per word than POS tags. For example, a word such as masterminded would have different SuperTags corresponding to its use as a transitive verb, in a relativized form, in a passive form etc. as shown in Figure 1.
![\begin{figure}
\centering
\rule[.1in]{\textwidth}{0.01in}
\small{
\begin{tabular...
...ve $\beta$N1nx0Vnx1}\\ \end{tabular}}\rule[.1in]{\textwidth}{0.01in}\end{figure}](img2.gif)
![\begin{figure}
\centering
\rule[.1in]{\textwidth}{0.01in}
\begin{tabular}
{ccccc...
...llary & companies. \\ \end{tabular}\rule[.1in]{\textwidth}{0.01in}
\end{figure}](img9.gif) |
Figure 3 depicts the
set of SuperTags associated with each word of the sentence the
purchase price includes two ancillary companies, where each
![]() and
and ![]() denotes a different SuperTag, representing
various non-recursive and recursive constructs respectively.
Since each word has several possible SuperTags associated with it,
the process of assigning the best SuperTag to each word, termed
SuperTagging [Joshi and Srinivas, 1994], is non-trivial.
denotes a different SuperTag, representing
various non-recursive and recursive constructs respectively.
Since each word has several possible SuperTags associated with it,
the process of assigning the best SuperTag to each word, termed
SuperTagging [Joshi and Srinivas, 1994], is non-trivial.
Local statistical information, in the form of a trigram model based on the distribution of SuperTags in an LTAG parsed corpus, can be used to choose the most appropriate SuperTag for any given word. This model of SuperTagging is very efficient (linear time) and robust: a system trained on 1,000,000 words of Wall Street Journal text and tested on 47,000 words correctly supertagged 92.2% of these words. For a detailed discussion of the SuperTagger, refer to [Srinivas, 1997a].
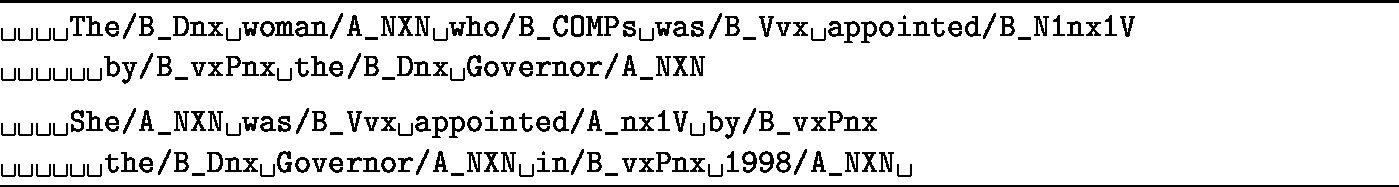
Figure 4 depicts the SuperTags assigned to each word of the phrase The woman who was appointed by the Governor and the sentence She was appointed by the Governor in 1998. Note that the SuperTagger distinguishes between the two uses of the word appointed, while part of speech (POS) taggers typically do not.
However, SuperTags do not encode morphological information about words (such as number and tense information), although attribute-value pairs are used to represent this information in the LTAG grammar that the SuperTags are based on. But SuperTags distinguish between the two different to's in, for example, I have to go to New York.
In the following sections, we describe a variety of language processing applications that use SuperTagging.
SuperTagging, the task of assigning the correct SuperTag for each
word given the context of the sentence, results almost in a parse for
the sentence. Combining the SuperTags is the only task that remains to
be done to arrive at a complete parse. Thus SuperTagging a sentence
before parsing reduces the load on the parser, and significantly
speeds up the process of parsing. Such an approach has
been adopted for the LTAG parser in the XTAG system. The parsing
process is faster by a factor of 30 when the SuperTagger is used.
However, a limitation of this approach of using the SuperTagger as a
front-end to a parser is that when an incorrect SuperTag is assigned
by the SuperTagger, the parser will not be able to parse the
sentence. Further, spontaneous utterances in the real world are
typically fragmented and sometimes ungrammatical. Thus the
SuperTag sequence assigned to the utterance may not be combinable into
one single structure. To handle this and related problems,
a novel device called a
Lightweight Dependency Analyzer (LDA), which exploits the dependency
information encoded in the SuperTags to arrive at a dependency parse
for an utterance, has been developed.
The SuperTagger in conjunction with the LDA has been
used as a robust partial parser [Srinivas, 1997a] and detailed
evaluation results for detecting noun chunks, verb chunks, preposition
phrase attachment and a variety of other linguistic constructions are
presented in [Srinivas, 1997b]. The performance of the LDA as a
dependency analyzer on Wall Street Journal and Brown corpus is also
presented in [Srinivas, 1997b].
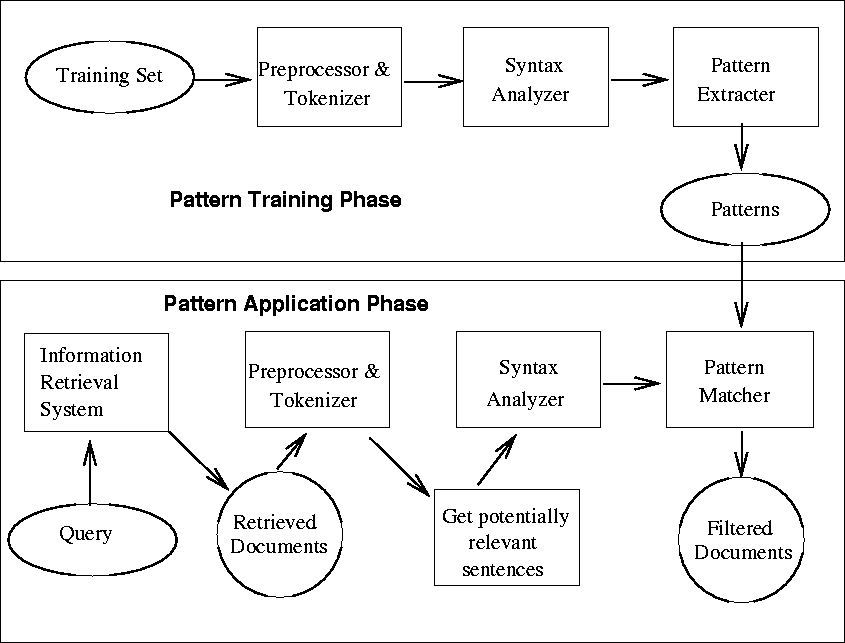
Figure 5 provides an overview of the Glean methodology,
while Figure 6 presents a schematic view of
selection and filtering in Glean.
This method was evaluated in filtering irrelevant documents [Chandrasekar and Srinivas, 1997b]. The
utility of SuperTags versus simple part of speech tags have been compared for
the same task [Chandrasekar and Srinivas, 1997d]. The effect of increasing syntactic context on the
effectiveness of information filtering is examined in [Chandrasekar and Srinivas, 1997c]. The system
has achieved recall and precision figures of 88% and 97% in filtering out
irrelevant documents. A version of the Glean system is now available on
the Web. An innovative method of server-side filtering [Chandrasekar et al., 1997] has
been proposed to improve retrieval efficiency on the Web. For an overall
summary of Glean, see [Chandrasekar and Srinivas, 1998a].
N-gram language models have proved to be very successful in the language
modeling task. They are fast, robust and provide state-of-the-art
performance that is yet to be surpassed by more sophisticated
models. Further, n-gram language models can be seen as weighted finite
state automata which can be tightly integrated within speech
recognition systems. However, these models fail to capture
even relatively local dependencies that exist beyond the order of the model.
We expect that the performance of a language model could be improved if
these dependencies can be exploited. However, extending the order of
the model to accommodate these dependencies is not practical since the
number of parameters of the model is exponential in the order of the
model, reliable estimation of which needs enormous amounts of
training material.
In order to overcome the limitation of the n-gram language models and
to exploit syntactic knowledge, many researchers have proposed
structure-based language models. Structure-based
language models employ grammar formalisms richer than weighted
finite-state grammars such as Probabilistic LR grammars, Stochastic
Context-Free Grammars (SCFG), Probabilistic Link Grammars (PLG)
and Stochastic Lexicalized Tree-Adjoining
Grammars (SLTAGs). Formalisms
such as PLGs and SLTAGs are more readily applicable for language
modeling than SCFGs due to the fact that these grammars encode lexical
dependencies directly. Although all these formalisms can
encode arbitrarily long-range dependencies, tightly integrating these models
with a speech recognizer is a problem since most parsers for these
formalisms only accept and rescore N-best sentence lists. A recent
paper [Jurafsky et al., 1995] attempts a tight integration of
syntactic constraints provided by a domain-specific SCFG in order to
work with lattice of word hypotheses. However, the integration is
computationally expensive and the word lattice pruning is
sub-optimal. Also, most often the utterances in a spoken language
system are ungrammatical and may not yield a full parse spanning
the complete utterance.
[Srinivas, 1996] presents an alternate technique of integrating
structural information into language models without really parsing the
utterance. It brings together the advantages of a n-gram language
model - speed, robustness and the ability to closely integrate with
the speech recognizer - with the need to model syntactic
constraints. This approach relies on SuperTags, which incorporate both
lexical dependency and syntactic and semantic constraints in a uniform
representation. It has also been demonstrated that this approach produces
better language models than language models based on part of speech
tags.
Thus a sentence such as:
will be simplified to a form such as:
In the first version of the text simplification
system [Chandrasekar and Suresh, 1995],
sentences were chunked using a finite state grammar (FSG),
and transformed by a rule-based system into simpler
sentences using rules from grammar and patterns from journalistic English.
Later, this was extended and improved [Chandrasekar et al., 1996], using SuperTagging and
the Lightweight Dependency Analyzer (LDA)
to extract predicate-argument structure. In both these
systems, simplification rules had to be hand-crafted,
a process that was slow and
error-prone. To solve this problem, LDA was used with an aligned training
corpus to automatically generate simplification rules [Chandrasekar and Srinivas, 1997a].
Word sense disambiguation (WSD) is a key problem in computational
linguistics, with applications in areas such as machine translation
and information retrieval. [Chandrasekar and Srinivas, 1998b] describe a
corpus-based method for word sense
disambiguation, which uses a versatile maximum
entropy technique on simple local lexical features and a rich
description of the syntactic context of a word to distinguish between
its various senses. Given training sentences which use a word in a
particular sense, a maximum entropy tool is used to build a model for
efficient word sense disambiguation. SuperTagging has been used to further enhance the quality of disambiguation. This method has been trained and evaluated
on two sense-tagged corpora: the interest corpus from NMSU and
the Singapore DSO corpus. For both corpora, the results obtained -
92.6% on the smaller (approx. 2400 sentence) interest corpus
and 72.1% on the much larger (approx. 192,000 sentence) but noisier
DSO corpus - are significantly better than previously reported
results.
Discourses refer to multiple entities each of which is
usually referred to by more than one linguistic
expression. Coreference resolution is the task of identifying
equivalent references for the same entity in a discourse.
Applications that involve manipulating (retrieving or deleting)
occurrences of a particular entity in all its various linguistic forms
stand to benefit from coreference resolution. In particular,
applications such as sanitizing text (where the facts about
certain entities are intentionally suppressed) and summarization and
information retrieval tasks (where only the facts pertaining to
certain entities are retrieved) are some examples where coreference
resolution is crucial.
Coreferences can be resolved using a range of language technologies
varying from simple string matching algorithms to the use of grammatical
information and to the use of sophisticated semantic and pragmatic
knowledge.
[The UPenn-MUC6-group, 1995] presents a system that limits itself to dealing with
syntactically resolvable coreferences but has good coverage. However,
it is too inefficient to be considered a viable runtime
application. Analysis of this system reveals that the inefficiencies
are due to processes that provide higher levels of linguistic analysis
such as NP recognition and full parsing. Preliminary results for a
system that utilizes SuperTags to provide
the necessary linguistic analysis within reasonable time are
then presented. The SuperTag representation also provides a direct
way of bringing to bear document level information, by means of
pre-SuperTagging words even before the syntactic analysis at the sentence
level is attempted.
SuperTagging and Parsing
SuperTagging and Document Filtering
The focus of work on document filtering is on Glean, a post-processing
filter aimed at increasing the precision of IR [Ramani and Chandrasekar, 1993]. Glean
exploits information latent in any text, such as syntactic structure and
patterns of language use. Augmented patterns defining relevance are
automatically induced from user-supplied examples, using the SuperTagger.
These augmented patterns are used to filter out irrelevant items from the
output of standard Web search engines or IR systems.
SuperTagging and Language Modeling
SuperTagging and Automatic Text Simplification
Most real-life texts,
such as news stories and computer manuals, are fairly complex when
evaluated by readability metrics. As an alternative to creating complex
tools to process such text, [Chandrasekar, 1994] proposed
the idea of text simplification: automatically transforming
complex sentences into a set of equivalent simpler sentences, which are
easier to process.
Talwinder Singh, who masterminded the 1984 Kanishka
crash, was killed in a fierce two-hour encounter.
Talwinder Singh was killed in a fierce two-hour encounter.
Talwinder Singh masterminded the 1984 Kanishka crash.
SuperTagging in Word Sense Disambiguation
SuperTagging in Coreference Resolution
References
A Hybrid Approach to Machine Translation using Man-Machine
Communication.
PhD thesis, Tata Institute of Fundamental Research/University of
Bombay, Bombay.
Motivations and methods for text simplification.
In Proceedings of the Sixteenth International Conference on
Computational Linguistics (COLING '96), Copenhagen, Denmark.
Automatic induction of rules for text simplification.
Knowledge-Based Systems, 10:183-190.
Gleaning information from the Web: Using syntax to filter out
irrelevant information.
In Proceedings of AAAI 1997 Spring Symposium on NLP on the World
Wide Web.
Using supertags in document filtering: The effect of increased
context on information retrieval effectiveness.
In Proceedings of Recent Advances in NLP (RANLP) '97, Tzigov
Chark.
Using syntactic information in document filtering: A comparative
study of part-of-speech tagging and supertagging.
In Proceedings of RIAO '97, pages 531-545, Montreal.
Glean: Using syntactic information in document filtering.
To be published in Information Processing & Management.
Knowing a word by the company it keeps: Using local information in a
maximum entropy model for word sense disambiguation.
Mss.
Sieving the Web: Improving search precision using information
filtering.
Submitted for publication.
Automatic text simplification.
In Proc. National Workshop on Software Tools for Text Analysis.
University of Hyderabad.
Disambiguation of Super Parts of Speech (or Supertags): Almost
Parsing.
In Proceedings of the 17th International Conference on
Computational Linguistics (COLING '94), Kyoto, Japan.
Using a Stochastic CFG as a Language Model for Speech Recognition.
In Proceedings, IEEE ICASSP, Detroit, Michigan.
Glean: a tool for automated information acquisition and maintenance.
Technical report, National Centre for Software Technology, Bombay.
Parsing strategies with `lexicalized' grammars: Application to Tree
Adjoining Grammars.
In Proceedings of the 12th International Conference on
Computational Linguistics (COLING'88), Budapest, Hungary.
``Almost Parsing'' Technique for Language Modeling.
In Proceedings of ICSLP96 Conference, Philadelphia, USA.
Complexity of Lexical Descriptions and its Relevance to Partial
Parsing.
PhD thesis, University of Pennsylvania, Philadelphia, PA.
Performance evaluation of supertagging for partial parsing.
In Fifth International Workshop on Parsing Technologies,
Boston.
Penn's MUC-6 Effort.
In Proceedings of the Sixth Message Understanding Conference,
Columbia, Maryland.
Subsections
![]()
![]()
![]()
For further information about the XTAG project and software
availability send mail to xtag-request@linc.cis.upenn.edu.
![\begin{figure*}
\centering
\rule[.1in]{\textwidth}{0.01in}
\mbox{}
\begin{tabul...
...uts.eps,width=6.4in}
}\end{tabular}
\rule[.1in]{\textwidth}{0.01in}\end{figure*}](img14.gif)